For users who are particular about pronunciation, the SynthV engine’s “guesswork” is at times more detrimental than it is beneficial.
I can’t see the internals of the program, so I don’t know exactly how the guessing works, but for the sake of explaining, I’ll categorize SynthV’s guesswork into two levels:
- Guessing the phonetic spelling of a word or syllable
- Guessing which vocal sample/ allophone to pull for a single phoneme
Let me preface this by saying I think #1 is a brilliant and helpful idea which is leagues better than just a dictionary (as in vocaloid) when initially inputting words & syllables. The problem arises during #2. Imagine the following scenario:
- User enters word
- SynthV incorrectly guesses phonetic spelling of word OR there is a glitch in the vocalization of the correct phonetic spelling that will require a workaround
- User goes into phoneme entering mode and changes/adds a phoneme in order to fix the problem
- SynthV incorrectly guesses which vocal samples/ allophones to pull for the new phonetic spelling OR the user is not able to get the program to choose the specific sample/ allophone they want
Now what is a user to do?
Let me a give a more concrete example that I ran into. I needed Eleanor to say the syllable “zing” in the word “freezing”.
SynthV correctly chose the phonetic spelling of /z ih ng/, however the “ih” was coming out sounding strained. No big deal, this sort of thing happens to vocal synths with a language like english, since it has so many phoneme combos and therefore a higher chance of hitting a weird transition. In order to fix this, I tried changing the phonetic spelling to /z uh ih ng/ as a workaround:
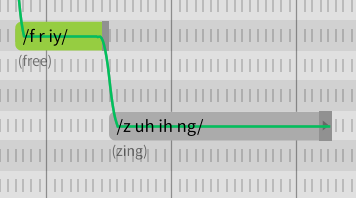
Inexplicably, that ^ phonetic spelling comes out sounding like this: https://clyp.it/5qbfm1fo
Where is that “F” sound in the second syllable coming from? What about that “R”-ish sound? This is just one instance in which I need to see what vocal samples SynthV is pulling.
I assume you, @khuasw, obviously don’t want to add a bunch of new phonemes for all the extra allophones. So, for a solution, I propose a “third level” of pronunciation editing.
If the first level is word input, and the second level is phoneme input, this third level would be vocal sample/allophone choice for a specific phoneme. Maybe like a dropdown menu off of a phoneme or something? Or even a new window?
Regardless, this issue is the number one thing keeping me from using SynthV right now. Without real control over pronunciation, fixing issues feels like shooting in the dark at a wheel SynthV is spinning based on factors the user can’t see. At least in Vocaloid, although you’ll have to spell many syllables from scratch, you know what you’re going to get when you enter a certain phoneme.
This is certainly a complicated topic and I’m no expert, but I hope I was able to articulate this well enough. After all, my perspective is that of a user, so I can only go off of my experiences and assumptions.
Thanks for reading.