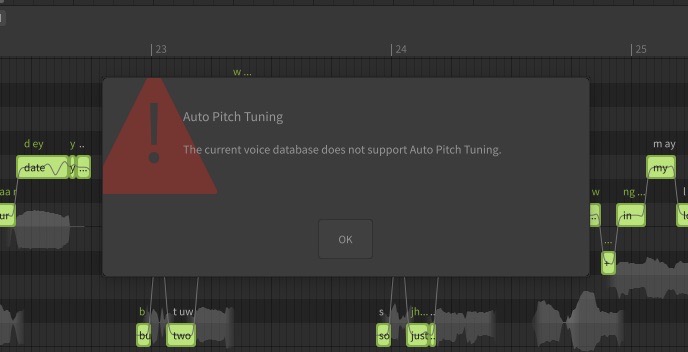
I can’t seem to get the Auto Pitch Tuning feature to work in SynthV Studio Basic. When I try to click on it, I get an error message saying that it isn’t supported by the voice database (I’m using Eleanor Forte Lite). Can someone help me fix this problem?
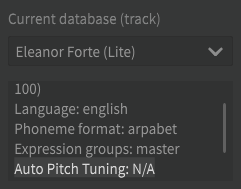
Eleanor Forte does not support Auto Pitch Tuning:
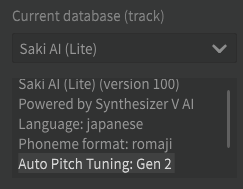
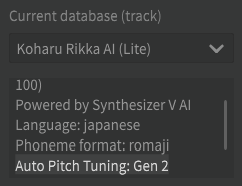
You need to use a voicebank with this feature, such as Saki AI and Koharu Rikka AI.
(Translate with translator)
Aww man I was really looking forward to using auto pitch tuning… Guess I’m gonna have to suggest an auto pitch tuning option for Eleanor in the Product Feedback tag. Thanks for letting me know.
You can still use Auto Tuning and Eleanor Forte. You’ll just have to apply Saki’s tuning to Eleanor Forte.
Install the free Saki AI (Lite) which does support Auto Tuning.
On the track that you want to Auto Tune, change the voice to Saki AI (Lite), select the notes you want to Auto Tune, and apply the tuning. Because Saki AI (Lite) has Auto Tuning, it’ll be applied.
The Auto Tuning will be written to the Pitch Deviation parameter track. Because Auto Tuning adds manual vibrato, it will also set the Vibrato Depth for those notes to zero.
Then switch the voice back to Eleanor Forte (Lite). Since the Auto Tuning was written to the Ptich Deviation track, the tuning will stay in place even when you change the voice.
I just tried this and it worked! However, there seems to be an issue. I applied auto pitch tuning to Saki AI and then switched the voice back to Eleanor like you said. I pressed play to see how my song sounded with auto pitch tuning added, and it… wasn’t good. She sounded off-pitch at many parts and it honestly felt like a downgrade from how it sounded before. Did I do something wrong? Does this always happen when you apply Saki AI’s auto tuning to Eleanor? Is there a way to fix it?
That’s normal. You can also experiment with shifting the voice up or down an octave, Auto Tuning, and then putting it back to the original register.
But Auto Tuning applies observed mannerisms to the vocal. They are - by their nature - human imperfections. For now, I think they’re best seen as a way to “humanize” the performance, and not a way to get a more “expressive” performance.
I suspect Auto Tuning is still at a fairly early development stage. With more songs or focus on specific styles, it’ll be better.
In the meantime, you’ll want to go back and manually add expression using the standard tuning tools.
And don’t forget to turn Vibrato Depth back on when you’re using the regular SynthV vibrato!
I should also mention that - in my limited experience - as far as “expression” is concerned, Tension, Gender and Loudness tend to be more important than pitch.
For example, if you want to give the impression of vocal effort, increasing Tension and Loudness are helpful. Singers also open their mouths wider when singing louder, which changes the shape of the vocal tract. This increases the frequency of the first formant - something you can simulate with Gender parameter.
None of these parameters are currently handled by Auto Tuning, and frankly, are a bit harder to measure and train a model on, so I’m not sure that I’d expect Auto Tuning to incorporate in the near future.
All of which is to say - Auto Tuning will get you part of the way somewhere - but to get a good performance, there’s still a lot of manual tuning to be done.
i need help with something, i know this thread is like 2 years old, but im having trouble tryna auto pitch my own track but its not being lighted up?
im using Anri for it she is supported!, its the latest version of synthv, but whenever i import a UST/VSQx or whatever into it i can auto pitch it…
If you have Sing pitch mode enabled in Note Properties, then auto pitch tuning is already being run on the notes in the background. You don’t have to run it yourself because you have an automatic pitch mode selected and that takes priority.
If you want to generate pitches on-demand (instead of it happening automatically every time you change a note), you first have to enable Manual pitch mode for the note, then select Auto Pitch Tuning from the Modify menu at the top of the application.
If you want to generate different pitches, but keep the automatic behavior, then add new retakes via the AI Retakes panel. Keep in mind that changing the notes after this will still re-generate the pitches due to an automatic pitch mode being active, so your retakes will not be permanent unless you lock them in by enabling Manual pitch mode.
 I was really looking forward to using auto pitch tuning… Guess I’m gonna have to suggest an auto pitch tuning option for Eleanor in the Product Feedback tag. Thanks for letting me know.
I was really looking forward to using auto pitch tuning… Guess I’m gonna have to suggest an auto pitch tuning option for Eleanor in the Product Feedback tag. Thanks for letting me know.