This is an issue that I’ve had for a while, since the AI voices were introduced. But, I remember in the old Synth V, raising the tension parameter would give the voice a more aggressive sound, and lowering it would give you a falsetto, soft voice. In the newer version of Synth V, that isn’t the case. Raising it does little to nothing, and lowering it just lowers the volume of the voice, which then you have to fix by raising the Loudness parameter. Can you please fix that? The tension parameter was one of the best features of Synth V.
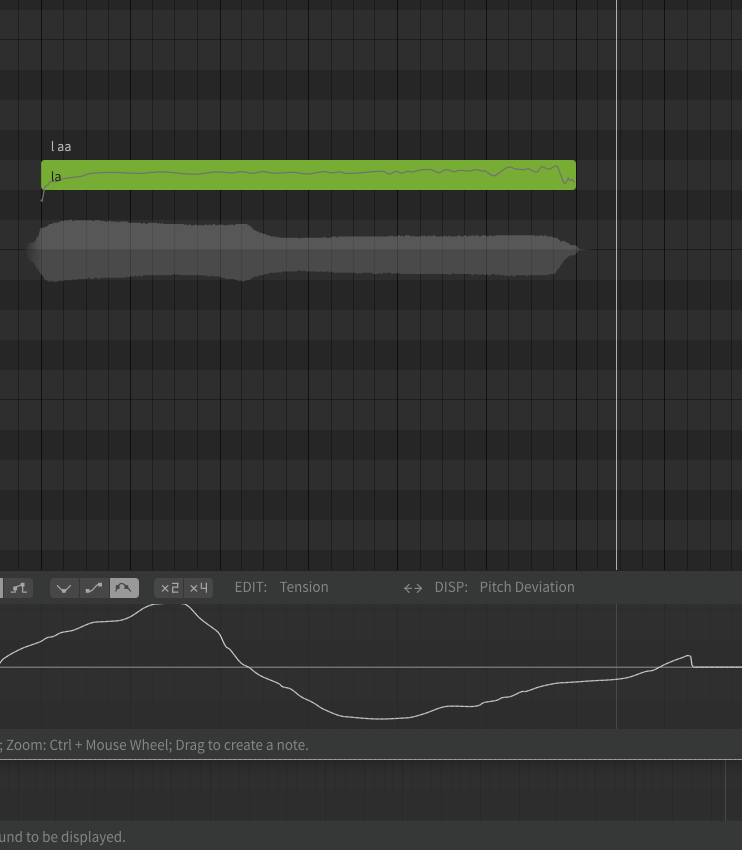
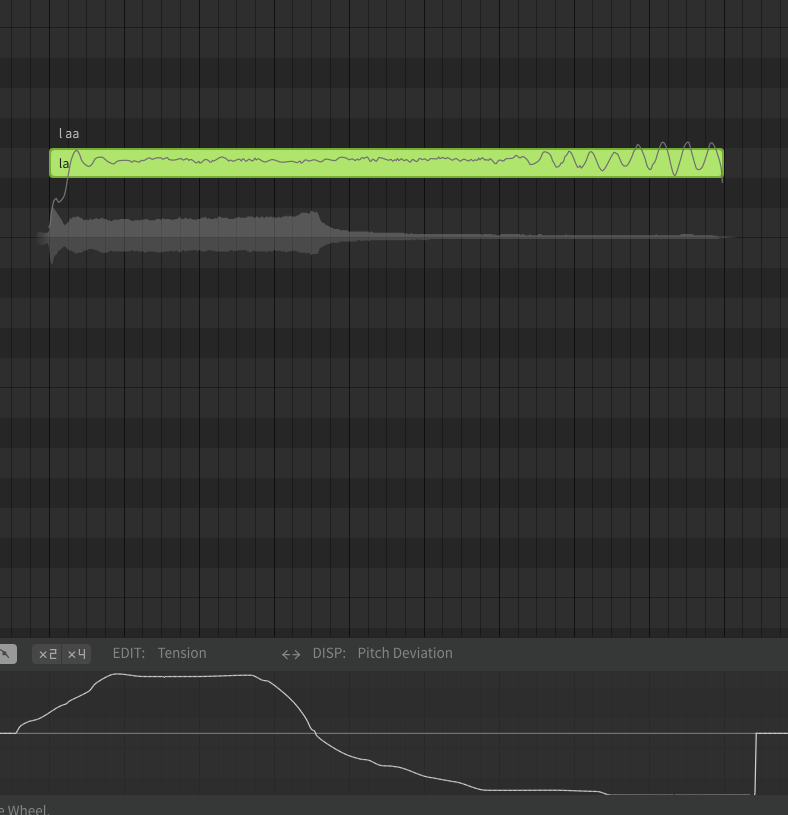
I did a test with the old Eleanor Forte and Solaria, and this is what the waveforms look like respectively:
As you can see, with old Eleanor, the volume stays mostly the same, and you do notice a significant change in the voice. But with Solaria the volume just goes down drastically. This only happens with AI voices, from what I’ve seen.
I expect this is because it’s actually two completely separate processes. The tension parameter for Standard voices is basically a post-processing effect run on the original samples, whereas for AI voices it is used to bias the AI engine toward a certain behavior.
I definitely agree though, it would be nice to have the tension parameter be more consistent. As-is it’s often too subtle to bother using with AI voices, whereas for Standard voices it can be a very powerful tool.
I agree! It used to be more consistent in volume! And I believe in earlier versions of studio pro, the AI voices handled tension a little bit better. From what I remember, I used to be able to lower the tension on the AI voices without the volume completely dissapearing. I think raising it still works as intended though, but all the parameter effects vary by voicebank.
IMO if I lower the Tension and raise the Loudness alongside each other, I am getting pretty close to the effect I remember. I think if nothing else, they should at least patch this by making the loudness/volume rise in a linear relation to tension decreasing (below tension level 0). That would help. But it’s possible that they should really just make sure each AI voice has some data source to reference for “soft” singing. Same goes for the other parameters, such as breathiness and loudness.
Instead of starting a new thread, I’ll add my 50 cents here.
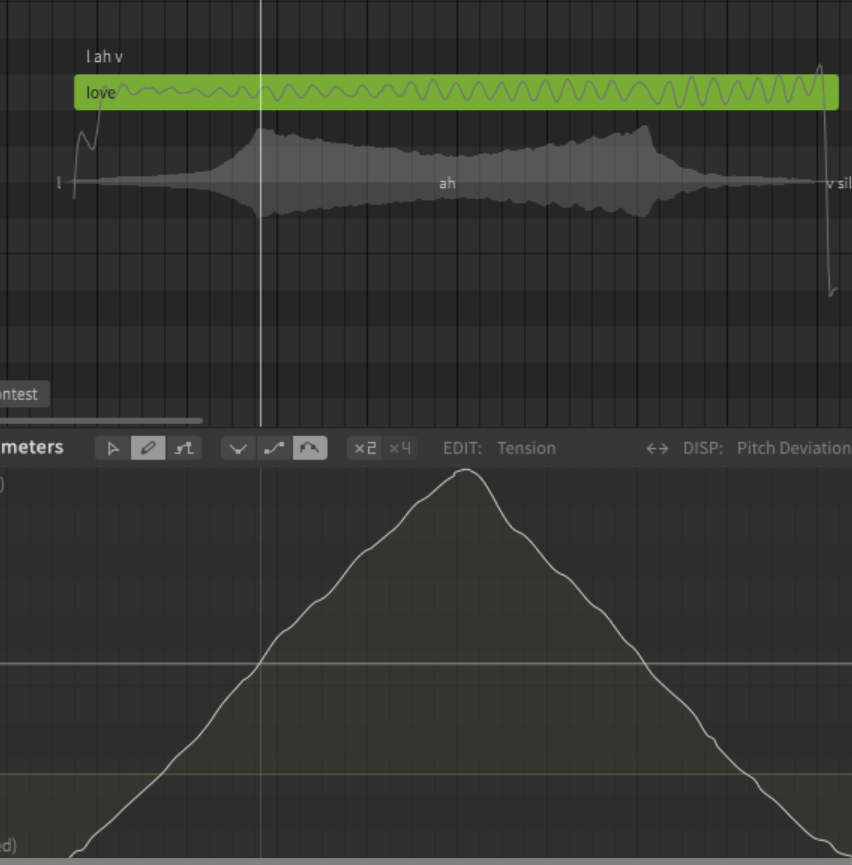
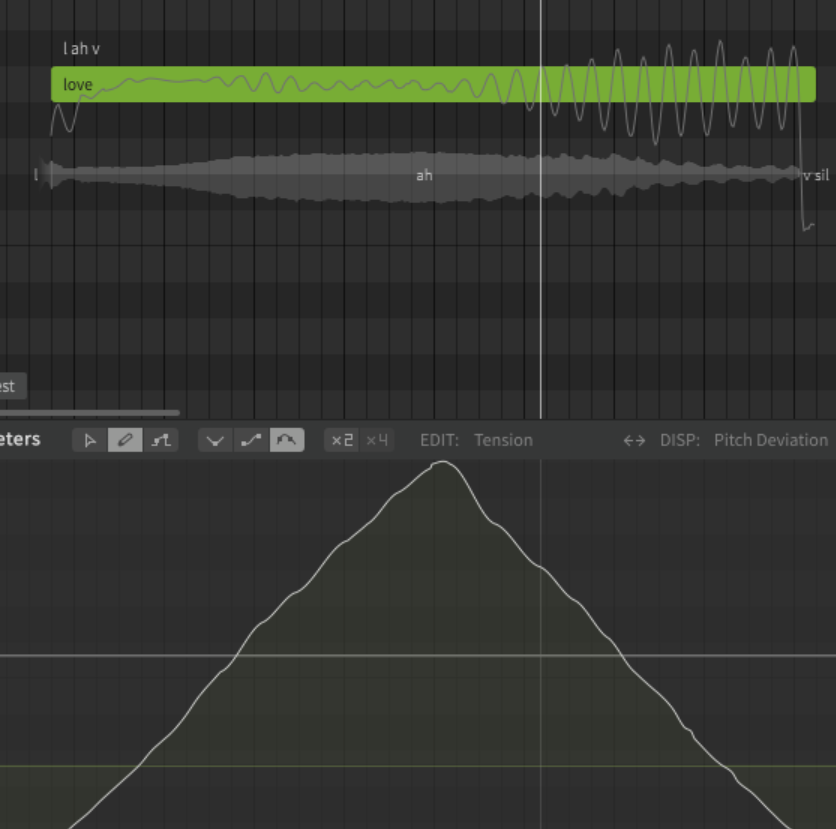
So I use primarily loudness and vocal modes for color and variation. I noticed today that the behaviour of the parameters, most noticably with “tension” are very inconsistent and it seems that it’s not due to some being AI (all are):
Natalie: fine
Asterian: smooth and fine
Ninezero, Saros and Solaria look like this (Solaria is the worst):