Would be very useful to have a default frequency as well as depth on the default Sing Mode vibrato.
You already have control over the vibrato depth. The Vibrato Modulation slider in the Voice panel and the global Expressiveness slider in the AI Retakes panel control the intensity of vibrato for an entire track or group.
This is an example of Asterian, who has the most theatrical/obvious vibrato patterns of any available voice database. Reducing these options almost entirely eliminates the pitch changes over the duration of the note. If you wanted an even “flatter” pitch line for an auto-tune/pitch-snap effect, I’d wonder why you’re using Sing mode at all.
In this example I’ve changed the settings just for the notes on the right for demonstration purposes, but you can do the same thing at a track/group level as well.
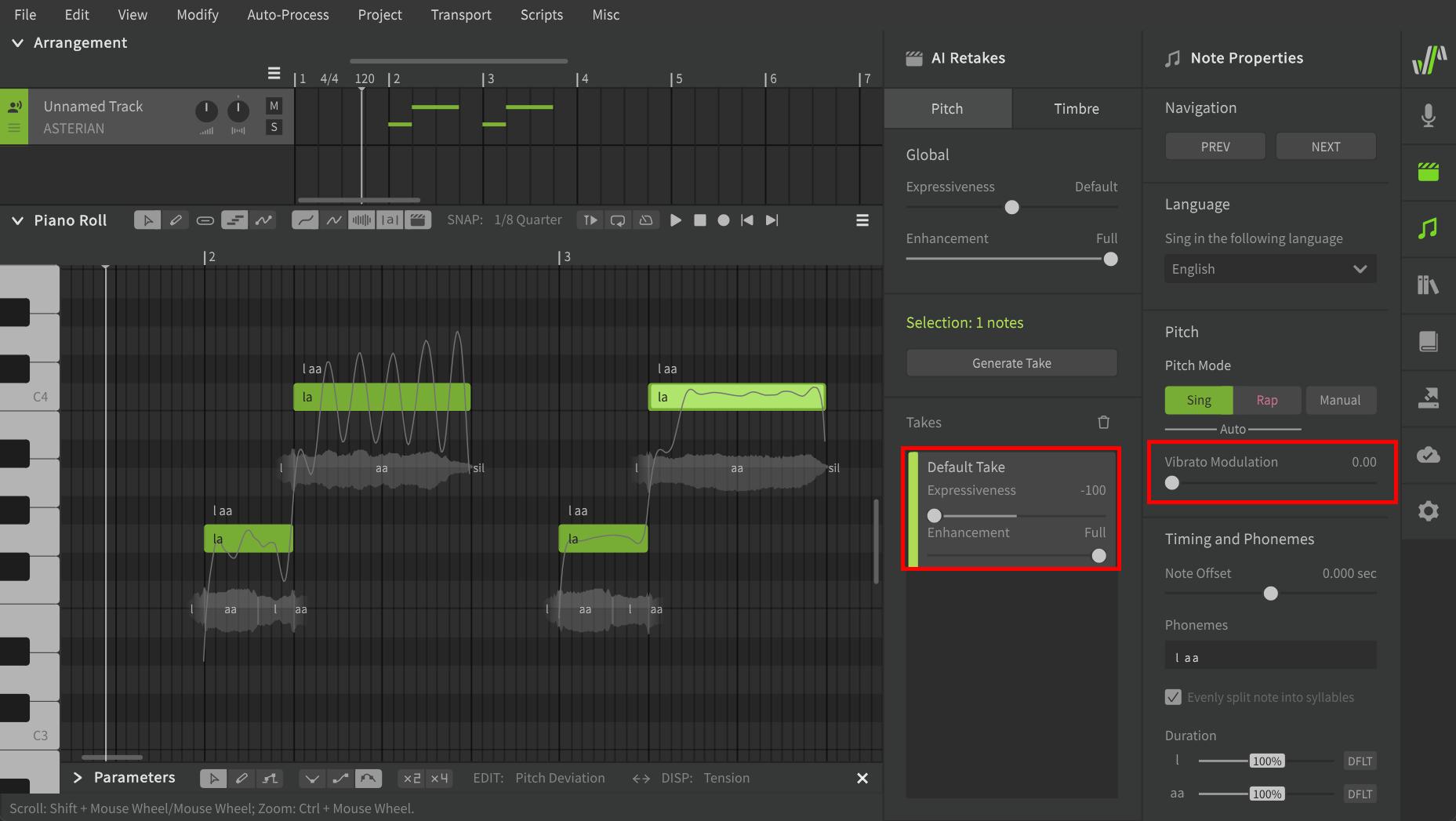
As for the frequency, it’s based on the vibrato used by the original voice provider. Currently there’s no way to control that, however if there’s a specific vibrato pattern you like, you can always “transplant” a pattern from one voice to another by setting the notes to Manual mode and copying the parameters curve directly.
Thanks Claire, I knew the depth could be adjusted in the panel. Didn’t know frequency was based on original vocalist.
I assumed it was artificial in the same way increasing the depth is artificial.
The depth is also based on the original vocalist. All pitch patterns generated by Sing and Rap mode are based on machine learning analysis of the original recordings used to create the voice database, and those recordings are heavily dependent on the voice provider’s personal singing style.
During this process, Dreamtonics tries to separate vibrato from non-vibrato patterns, so that the vibrato can be scaled with the VIbrato Modulation slider separately from the note transitions. But of course, the original recordings don’t have separate vibrato and non-vibrato pitches, it’s just one voice.
For this reason the Vibrato Modulation scaling isn’t purely mathematical – or at least, not in the way you might assume. “1.50” doesn’t increase the generated vibrato by 50%, it just adds a bias to the AI model so that it considers more intense vibrato to be 50% more desirable than usual.
(to be clear, the pitch models are almost certainly built on top of some common base model, which is why voice databases with no rap data can still use rap mode, but whenever there is pitch data from the voice provider, it is given higher preference in order to give each product individuality and reflect a specific style)
Yes, but not enough and regarding a discussion in another forum, I’m not the only one, who finds, that the minimum vibrato setting is still too high. Example: Saros.
The pitch fluctuations shown in my screenshot above are extremely minor and could barely qualify as vibrato at all. If you want an even flatter pitch curve so that there are no fluctuations at all, you probably shouldn’t be using a pitch generation mode that is explicitly designed to introduce fluctuations.
I must have done something wrong, sorry.
I did a second test and set the vibrato for the shown note to zero … sounds good now.
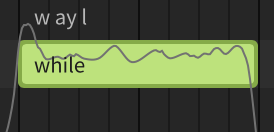
I will do further testing, but I’m confident now, that it will work … if not, I’ll report back ![]()