Anyone or just me? AI voices Gen 3 have “s” “sh” “z” “f” “h” “ts” sound jaggies not smooth like Gen 2.
「いいね!」 1
i’ll test this out with saki ai & tsurumaki maki eng & jpn, and see how they are.
apologies, but I only have lite versions of these voicebanks, and so the results may not be the same!
can you explain in more detail how the sound has a jagged-like texture to it? is it visible, or is it just in the audio?
(native english speaker, machine translated japanese and chinese)
Well, the jaggies only exist in full version quality render of voicebanks. The more length of “s”“sh”… the more noticeable.
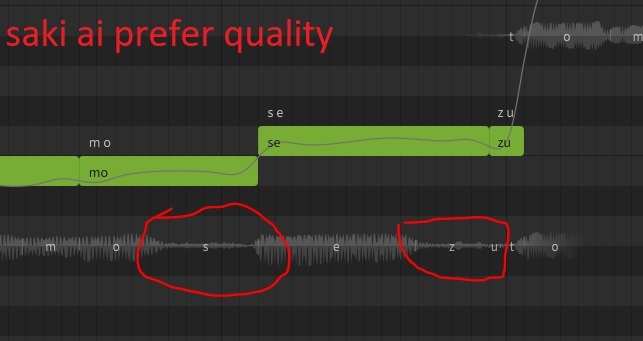
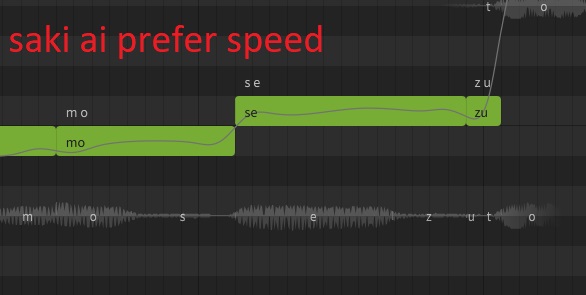
And you can notice how gen 3 breath sound jaggy compare to gen 2 in the Gen 3 demo.

I’ve noticed that too. It seems like Eleanor often pronounces the /ih/ phoneme as /iy/
弦卷真纪AI(英语Lite)发音bug。
twin、knew、grace、present、embrace、free这些单词中间的w、y、r音会被识别为普通的元音,发音长度占整个音符的一半。爱莲娜·芙缇(Lite)和弦卷真纪(英语Lite)的发音就是正确的,w、y、r只占很短的发音长度,普通的元音发音长度占音符的大部分。
Eleanor Lite still can’t pronounce the following words:
tears, transient, waiting, if/it, ignore, said
tears has the following phonemes: t eh r z, if I change /eh/ to /iy/ it sounds better
transient is tr ae n s iy n t, which is almost correct but it misses an /eh/ after /iy/
waiting is w ay dx ih ng, I replaced /ay/ with /ey/
if and it, I haven’t really managed to find a way to fix that. In both cases the /ih/ phonemes sound like /iy/. I found that with an instrumental truck running and splitting the note to one short /ih/ and one longer /f/ or /t/, it sounds “almost” okay, but without music it sounds very odd
ignore, she usually uses the correct phonemes (ih g n ao r) but sometimes she also switches from /ao/ to /eh/ and I’m not sure why
said, the phonemes are s ey d instead of s ae eh d
For some cases, the dictionary is simply wrong.
In others, there are two options because there are heteronyms, so the alternative for tears is /t ih r z/
For transient, try /tr ae n - z iy - ih n t/.
Waiting is /w ey - dx ih ng/
if and it can be replaced with /ih v/ and /ih d/ and devoicing the stop consonants by editing the Voice parameter. Not perfect, but you can make it usable.
The full version of the SynthV editor allows using alternative phonemes, which is probably your best solution.
I see thanks for telling me
Hello, it’s me again. Does anyone know how to make Eleanor sing “yeah”? The phonemes are /y ae/ and changing it to /y eh ax/ or /y ea/ doesn’t give me the desired output or doesn’t work
I recently purchased the pro version
How about /y ae h/?
The /h/ will add a bit of aspiration to the end, which seems to be what you’re looking for.
Don’t forget that you can choose alternate phonemes using the Note Properties panel, and adjust the phoneme durations there as well.
Hi! Does anyone know of a better way for Eleanor (Lite) to pronounce ‘noise’ than /n oy z/ ? It sounds like she saying ‘nose’ with a ‘z’ sound.
The best I could do is /n ow iy z/ and adjusting the duration of the phonemes until it sounds okay.
(I’m using Synth V Studio Basic.)
Try breaking it up into two adjacent notes of the same pitch, /n ow/ and /oy z/.
Make /n ow/ sufficiently small, like a 16th note.
Wrong phonemes is a big motivation for getting the non-free version, because you’ve got alternates to choose from.
Thank you for your suggestion. I was able to get passable results by editing the duration of / ae / but I will also try it with the / h / at the end
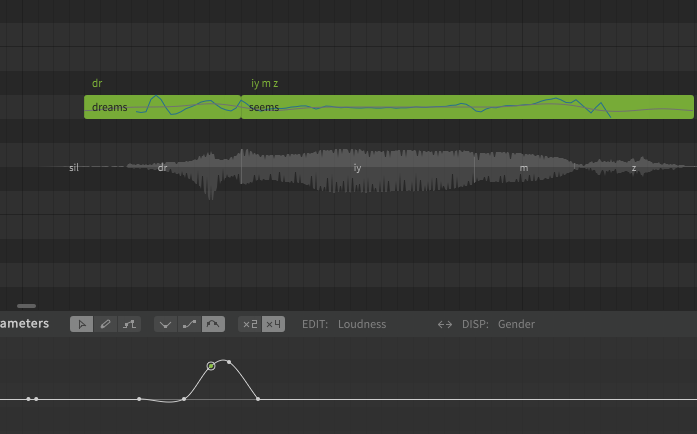
Another question, I’m having problems with Eleanor singing dreams / dr iy m z /
If I separate the phonemes to /d r iy m z/ it sounds slightly better, but the /iy/ is then pronounced as /eh/
I tried splitting the notes and changing the duration of the notes but it doesn’t sound as good. /d r iy/ sounds okay, but if the note is near /m z/ it sounds odd again
Urgh, this one’s tough.
There’s the trick of replacing /dr/ with /d r/, but in this case, it turns the /d/ into a /b/. 
Splitting it into /dr/ /iy m z/ is slightly better, but a bit bumpy.
You can try finessing the volume with the Loundess curve, but the results aren’t great:
Found that if you give a word “fed”, you will get /f t/ instead of /f eh d/
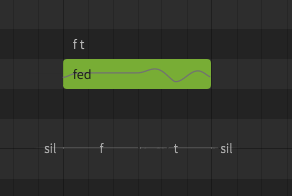
( using the Lite Versions of Eleanor and Maki AI in a Basic Studio)
Found that wind is pronounced as /w ay n d/ instead of /w ih n d/ (Both Maki and Eleanor)
I also found that if you want to split “worthwhile” it doesn’t do that correctly. Instead of
/w er th/ /w ay l/
it’s
/w er/ /th w ay l/
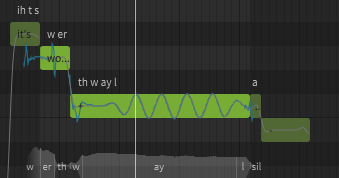
For “wind”, /w ay n d/ refers to “turning”, as in “wind a clock”, as opposed to /w ih n d/, which refers to air in motion, as in “the wind in the willows”.
They are both valid, so SynthV probably just picks the first one in the dictionary.
Yeah I realized that after writing that, Sorry 
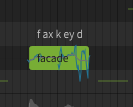
I also noticed that both English lite voices can’t pronounce “facade” because it turns to /f ax k ey d/
That’s odd.
SynthV uses the CMU Pronouncing Dictionary for most of the text-to-speech, and facade is listed as /F AH S AA D/, and that’s the only listing for the word (ignoring the pluralized version).
Maybe the latest version of SynthV uses a neural network to do the pronunciation? That would be an odd decision, since it’s guaranteed to be less accurate. 
No this error existed before the recent update (I was working on “Can’t I even Dream” when I noticed this strange error and that was before 1.4.0) and I checked and I’m using the program’s default dictionary. I have tried to start the benchmark for the DNNI but it didn’t change anything