1.I really do love the vocal mode so much it is very expressive, however, a natural voice moves between different timbre and synth v currently only allows vocal mode applied to a whole track (and if i separate it to different tracks with different modes that’s too messy and consonants/vowels transition will be weird). Could Dreamtonics please have a function that I can pick a single note or a group of notes with a certain vocal mode in the same track because that would help tremendously with the tuning process for me (I think that makes more sense than a drawing-based vocal mode because the sound will be low quality and muffled).
2.Another thing I would greatly appreciate are velocity and strength parameters. Sometimes I really want to control velocity of consonants (or strength of vowels) of a group of notes or the whole track but synth v only allows me to edit that manually per note in note properties and that is very time-consuming.
But you can use Groups to do something quite similar.
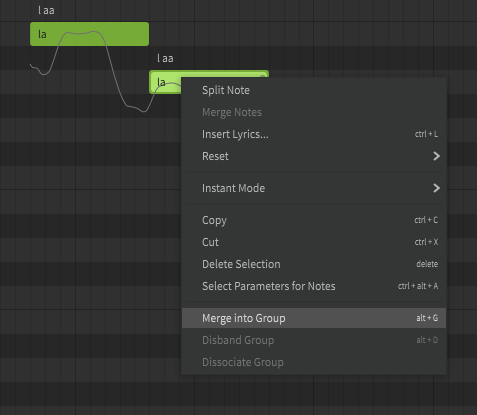
If you select a set of notes, and then right-click, you can choose Merge into Group to make the notes a Group:
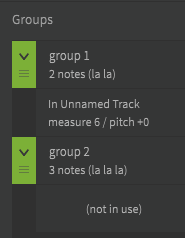
There’s a panel for Groups that you can open by clicking the icon with the three books:
You can rename the Group in the panel, if you wish:
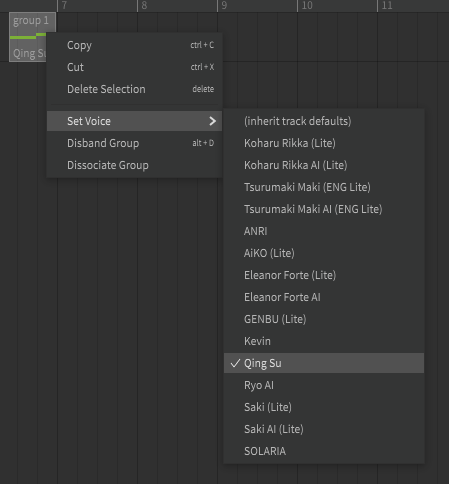
By default, the Voice used in a Group is inherited from the Track. If you click on the Group
in the Track, if you right-click on a Group, you can assign a different voice to the Group:
If you do this - but assign the same voice, you’ll then have a new instance of that Voice for the Group. You can then change the attributes for the Voice associated with the Group.
Be sure you select (double-click) the Group before you change the Voice attributes, so you don’t accidentally change the voice attributes for the voice assigned to the Track.
Yes, technically, you can group notes and pick vocal modes separately for each group (and all of these groups are within the same track); however, I am not satisfied with the rough audio transition of notes between these groups. Because they are all very distinct timbres, the notes transitioned from one group to another (if in opposite vocal modes) tend to be sharply different in volume, consonant, and vowel and even cause a sharp pitch jump. That’s why I would prefer if Kanru Hua could program more on the transition of the different vocal modes maybe with fade in/out, transient vocal mode blending, or something along that line.
I totally agree with both of these. I’ve been trying to find ways of adding natural dynamics and tonal variations within phrases, and I’ve been quite frustrated by the difficulty in doing this. Hopefully, these will be developments as Syn v continues to evolve.
Hi there
I am running version 1.10.1. Any change in vocal mode affects all notes in a track. The request you refer to (and with which I agree) is the facility to be able to alter the mode for individual or groups of notes within a track.
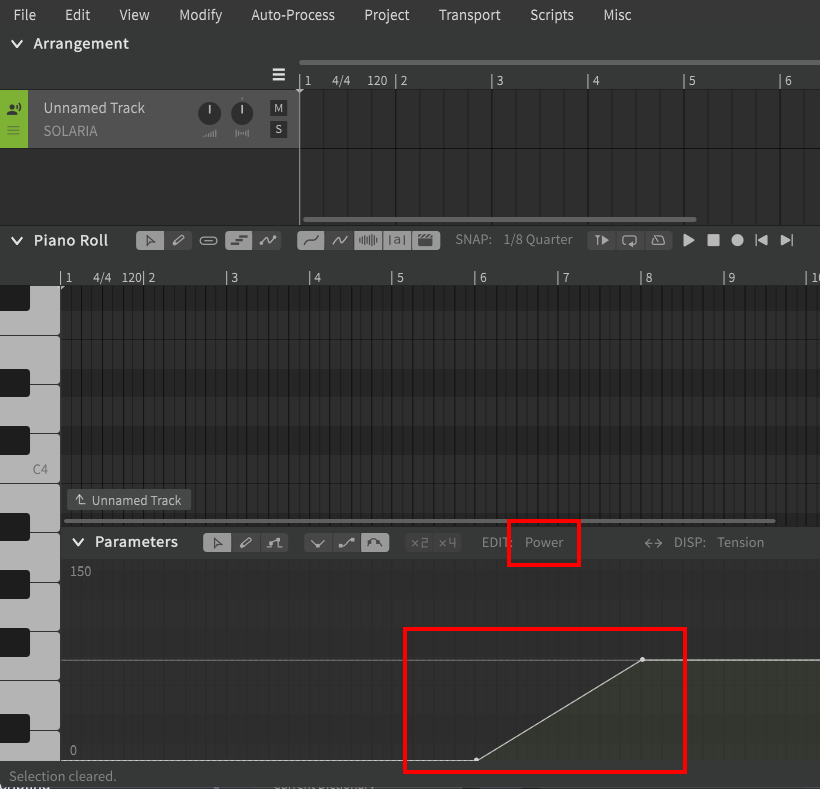
Then if I change the base value to 50, it is now changing from 50 to 125 over the same duration. Notice how the parameter curve modifies the Vocal Mode from the base value set in the Voice panel in a moment-to-moment manner.