In order to train the AI to sing in different ways, it’s very likely they need to tell the AI which learning materials (ie the recorded samples it analyzes) are in which style, so that the AI can build associations.
In other words, by default the AI’s learning algorithm simply analyzes songs, but it has no concept of “soft”, “whisper”, “belting”, etc. Vocal modes are most likely created by providing the AI additional context for the things it has learned so it can observe a new type of pattern.
(please note this is speculation based on what I know of machine learning in general, and the actuality may be different since Dreamtonics is quite secretive about their processes)
The exact modes for each voice and the words used to describe them would likely be dependent on:
The recorded samples available - how many different songs did they get the voice provider to record, and how much stylistic variety is there within that set (ie, “in which ways can the learning materials be categorized?”)
The voice character/avatar/mascot - what type of voice is the product marketed as, what kind of focus does the company want for their specific character, and which modes/styles support that image
Going by what you’re saying with the second point there, you can very clearly see this with ANRI. It seems the image in the tweet hints to what she is getting: Emotive, Chill, Light, and the fourth seems to be “Charm” as written on her top. Very matching in her character if this is true.
Not too much news from today’s TOKYO6 livestream about the Vocal Modes, but they’ve mentioned that Karin and Rikka are progressing. Chifuyu will also have Vocal Mode (5 variations) added in and they hope to have it completed by the time she releases (October), but I won’t further share much more about it since she has her own dedicated threads and they’re aiming to have it done for her final release (Synthesizer V AI Hanakuma Chifuyu (花隈千冬): New Japanese Female Voice from TOKYO6 ENTERTAINMENT and Synthesizer V「花隈千冬」即将众筹). If for whatever reason she ends up NOT getting them within her first release version, then I’ll mention her more here.
Mode 1: Clear
Clear provides a bright voice that helps SOLARIA pierce through the mix of any song to be heard clearly! When mixed with other modes or her default voice, it can be used to naturally raise the brightness of her tone without relying on effects in mixing.
Mode 2: Soft
Soft gives SOLARIA a gentle and mellow tone, stripping out the natural power in her voice to give the user discrete control over her expression, with added breathiness and darkness to the voice.
Mode 3: Airy
A whispery mode that provides a unique tone. While similar to Soft, it removes the support from SOLARIA’s voice, leaving only a light and gentle quality. This can create unique effects as backing vocals, or add a new layer of expression for more atmospheric vocals.
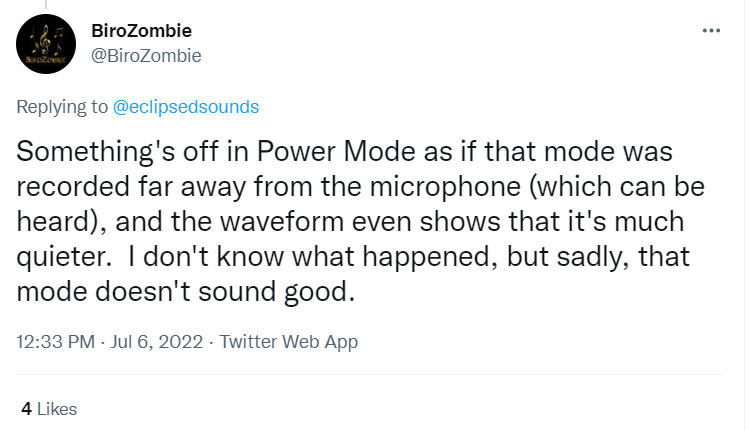
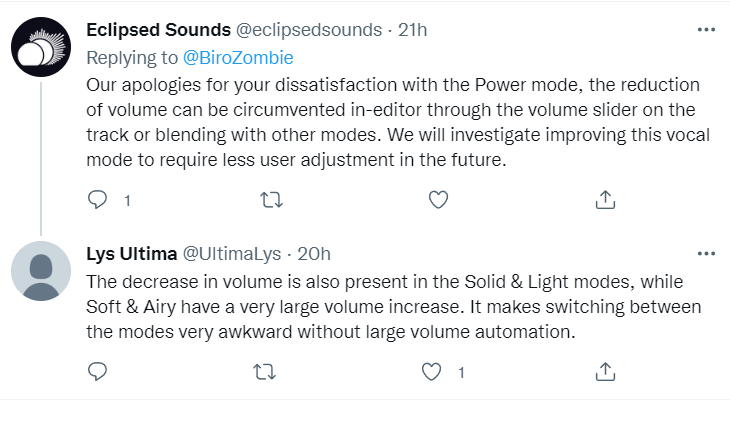
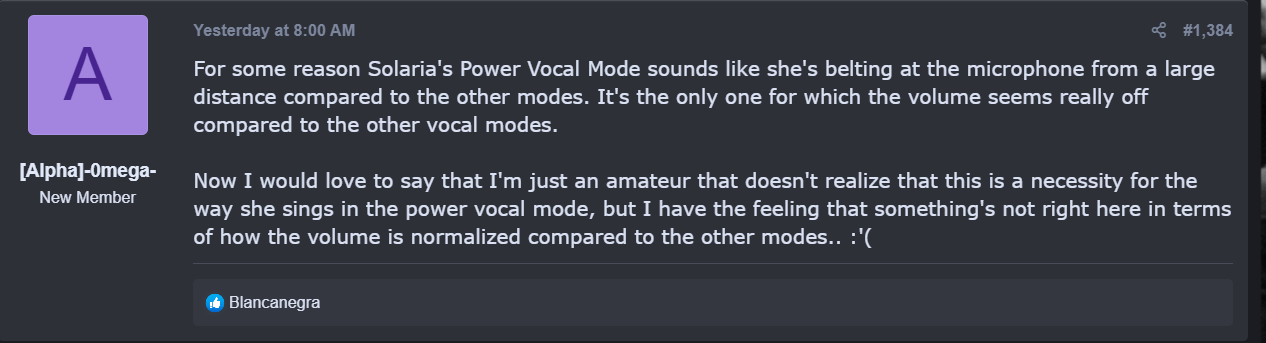
Mode 4: Power
Power brings out SOLARIA’s belting ability directly, lending a strong, emotional voice to the user even more easily even just after install.
Mode 5: Passionate
Passionate is the closest to SOLARIA’s default tone, and it is based on the most emotional lines of each of the songs in SOLARIA’s data, increasing her natural emotional expression.
Mode 6: Solid
This mode packs energy into every syllable, helping to bring out a different side of SOLARIA’s strong tones. When mixed with other modes or her default voice, it can add a base of support to add punch to the vocals.
Mode 7: Light
A mode based only on the upper part of her range, typically described as “head voice,” light can provide a unique tone across the range, with bright high notes and more solid low notes. It is best used for songs in a higher register.
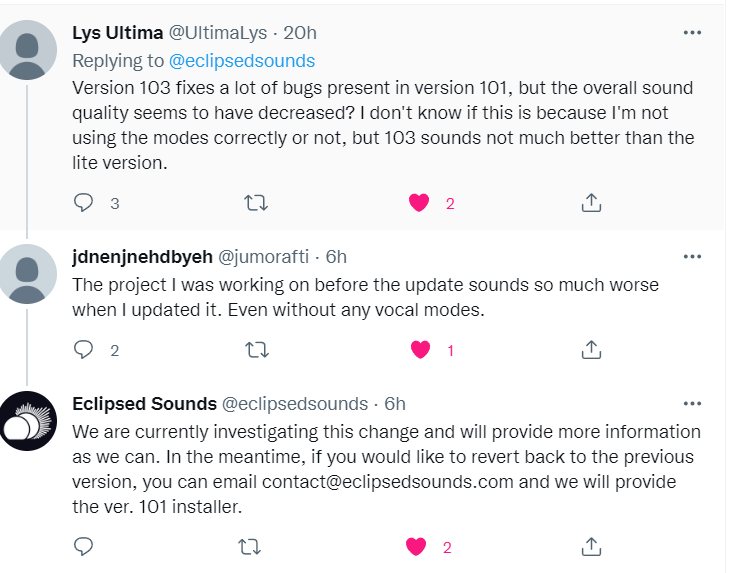
SOLARIA v104 is here! This should correct the sound quality issues and improve the tone consistency. There will still be some improvements to be made in the future, but at least we got an update rather quickly.
Do keep in mind that Cangqiong and Muxin are being repackaged as AI banks using their original Standard voices as a basis, rather than by recording new materials. There is no guarantee that this method will allow for vocal mode support.
While I certainly do hope the Quadimension AI ports turn out well, I’m hesitant to get my hopes up since they are not being made in the same manner as existing AI voices.
Synthesizer V Studio got updated to 1.8.0b1. Along with the beta voice databases, Rikka ended up getting her Vocal Modes along with it: Kawaii, Soft, Pops, Emotional, and Ballade.
Eleanor ended up getting them too, but VOLOR announced that they still need further testing. We are also expecting demos for the Eleanor Vocal Modes
Eleanor Vocal Mode demos dropped! She’s getting 8 in total: “Solid”, “Tender”, “Bold”, “Melancholic”, “Powerful”, “Dark”, “Warm”, and “Clear”. The 108b1 installer that’s compatible with version 1.8.0b1 will be coming out early next week. .w./
Long time no see on this thread. We have a new update confirmed for one of the older AI voices who released pre-vocal mode. According to JUN’s newest demo, he has a mode known as “Tsubaki” which was noted to have data that was designed specifically to improve Japanese Cross-lingual Singing Synthesis.
ANRI was noted to have a similar update in the future. Figured to probably add this info here.
")





 [ENG→JPN XLS] [英語→日本語 「多言語歌声合成」]")