Dreamtonics has announced that ARA support will be demonstrated at the upcoming Music China event.
Now that 1.10.0 has arrived, we can likely expect to wait for the next major update before these features arrive, possibly along with Japanese rap support and the four new Dreamtonics voice databases.
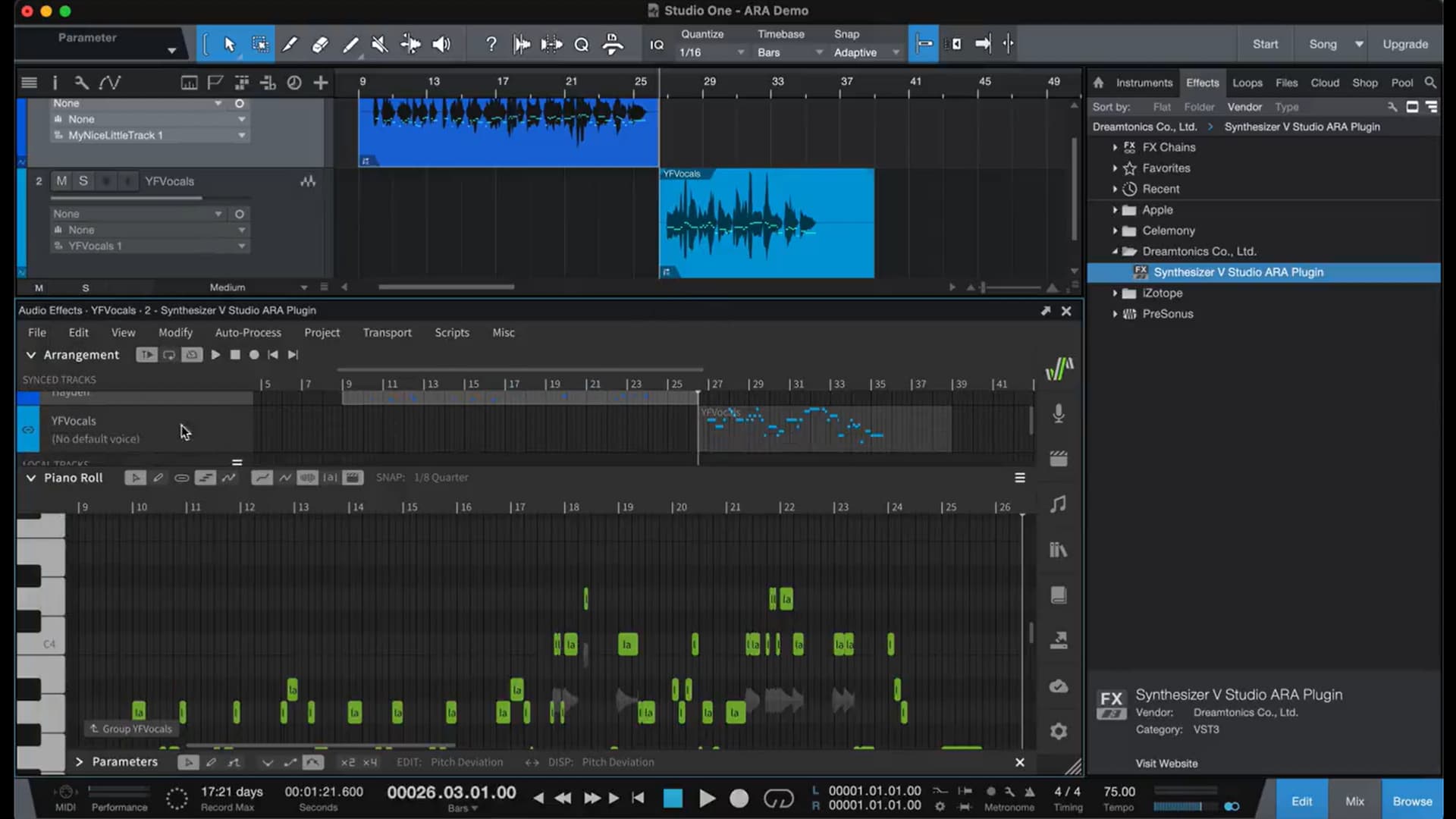
ARA support is a long-requested feature, which often raised the question “okay, but which parts of ARA will they use, and what will they do with it?” Based on the video and text of the tweets, the following is confirmed:
Playhead and tempo synchronization
Track synchronization between the DAW and SynthV Studio, where audio clips in the DAW are automatically represented in SynthV Studio as groups in the arrangement
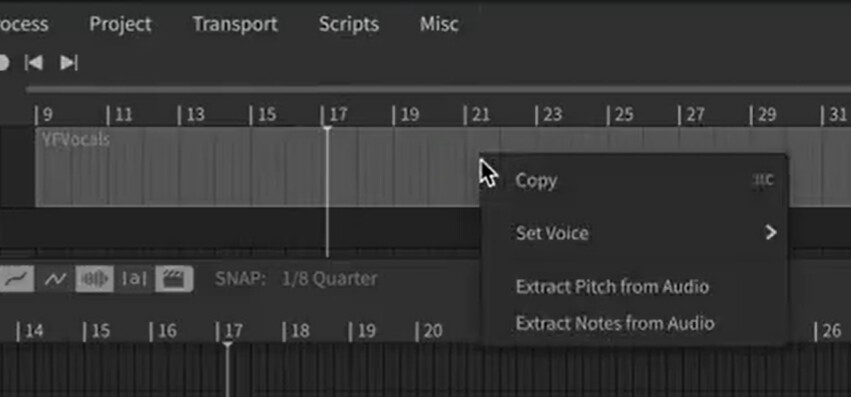
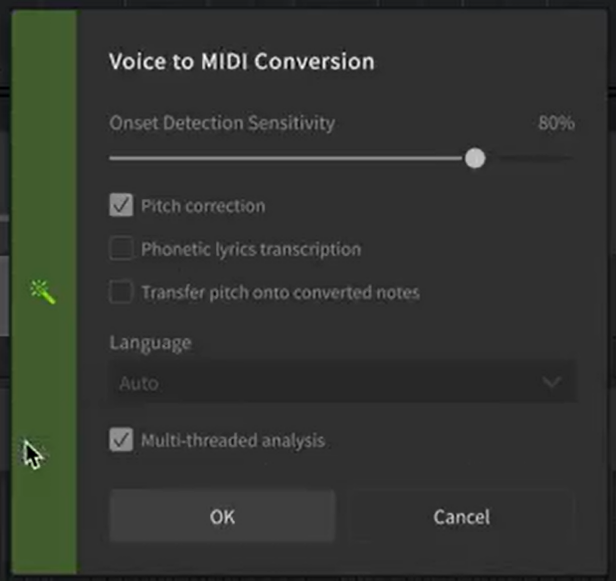
Additionally, wav-to-MIDI conversion allows quick creation of tracks in SynthV Studio from a vocal recording. This function can read audio data directly from the linked DAW track, and includes:
Notes
Phonetic transcription (optional)
Detected pitch curve to match the original recording (optional)
Thanks Claire for sharing this info. I saw another thread in the forum about this and I was curious about what functionality an ARA integration would bring outside of transport sync. This surpasses what I was expecting. Dreamtonics seems to be moving quickly to add features that makes the software better and better so, hats off to them.
Claire, do you have any idea of what the Phonetic lyrics transcription functionality will do?
I can only speculate based on what was said in the post by Dreamtonics, but it’s almost certainly going to assign phonemes to the notes based on analysis of the original vocal sample. It’s likely optional because the accuracy will probably be heavily reliant on how clearly the vocalist sings the lyrics. Additionally, some people might sing a melody with hums or "la"s because they only care to transcribe the melody itself and prefer to enter the lyrics in the software afterward.
People often don’t pronounce words “properly” or enunciate clearly when singing, especially given the scale of potential melodic and rhythmic variation any set of lyrics might have. This means that inferring the actual lyrics would be significantly more complex than normal speech recognition; the next best thing is trying to identify just the phonetic content.
Usually users will manually adjust the phonemes in SynthV to get a more natural sound, to mimic the shortcuts humans use when speaking or singing such as catenation and other types of connected speech. A simple example would be changing “don’t you” to “don-chu” or even “doncha”; the default phonemes for those words may be correct, but people often speak or sing things differently than what is “correct”. “Don’t you want to” can easily become “doncha wanna”.
The phonetic transcription feature is doing this same process almost in reverse. Rather than starting with lyrics and trying to achieve a certain pronunciation, you start with the pronunciation and the software tries to reproduce it.
Wow, finally a positive update for me, “could” be a workflow changer
Hopefully it’ll be fully integrated with Cubase and most important stable
Shame you can’t hear the original Audio vs the Output in the released video
So many questions this topic raises, I guess time will tell
THANK YOU for the info claire!
Thanks for your response Claire. That is what I was hoping the feature was going to be but, I thought it may have just been wishful thinking on my part. I can imagine extracting the phoneme info from audio is a difficult process and will be far from perfect. However, even if the software could get a decent amount of this info correctly recognized, it seems like this would be a big time saver. I am definitely looking forward to the demo to see if more details are revealed.
This is great news and will stabilise especially tracking in Logic I hope. Wav to midi I now do with Melodyne but of course is welcome as an integrated feature. I hope the wonderful people at DT go that extra step to really get those phoneme syllable distinctions in without having to divide up recognised words by hand. I look forward to testing this!
I was wondering if it picks up the note and even picks up note bends or vibrato, once you type in the words will it keep that information or just resample?
If the note is using the automatic pitch curve of Sing mode, then modifying it will immediately re-generate the pitch.
If Manual mode is toggled on, then it won’t.
That’s core functionality that probably won’t change based on how you import the notes.
Of course, if the automatic phoneme detection enters the phonemes above the notes as green text then changing the lyrics inside the note will do nothing to the output unless the phoneme override is cleared.
A post on Instagram has stated that Studio One and Cubase will be the only DAWs initially supported for SynthV Studio’s ARA capabilities, with more DAWs to come in the future.
This could just mean that those two DAWs are the only ones that have been tested, however it’s also possible that the ARA capabilities won’t work at all in unsupported DAWs; it’s unclear as of yet.
Amazing. I had emailed them about getting Audio to Midi and text implement into SynthV a while back and I’m so happy that they listened to my suggestion. I’m really looking forward to this update, this is definitely game changing. My only wish left, is that I’m hoping that they add a “Snap to Scale” functionality in the Piano roll, similar to how FLStudio has it on their Pianoroll. I will email them about it.
Yes, it streamlines the process where people would use Melodyne or similar software to generate MIDI and then import that to SynthV Studio, with the added benefits of phonetic transcription and pitch curve detection.