So make a long story short I’m wanting to make a Solaria Cover of Ode to Joy in German, the issue being I don’t speak German. I’m aware of the dictionary, but it’s imperfect and a lot of words didn’t get properly transcribe when I tried to use it. They were missing. And apparently a lot of the words it did fix doesn’t sound right, at least according to my German Friends.
When I bought Saros from Eclipsed Sounds, it came with a German dictionary, but I didn’t really test it … just had a short look, which looked quite ok.
But this dictionary is huge and causes a delayed start of Synth V.
I can confirm that, I live in Germany.
The “ENG-GER1.0_EclipsedSounds.json” dictionary provided by Eclipsed Sound is very comprehensive, but does not reflect many words in the best possible way.
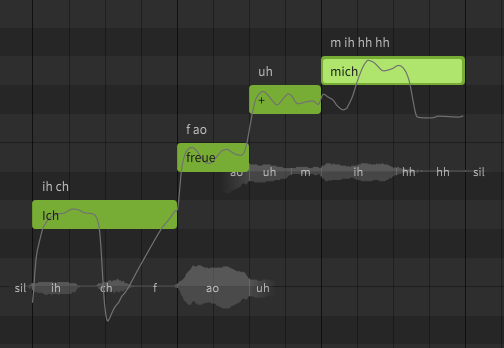
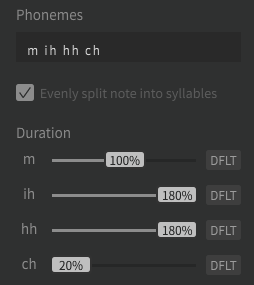
An example is the simple sentence “Ich freue mich” (= I’m happy).
With the dictionary mentioned you get:
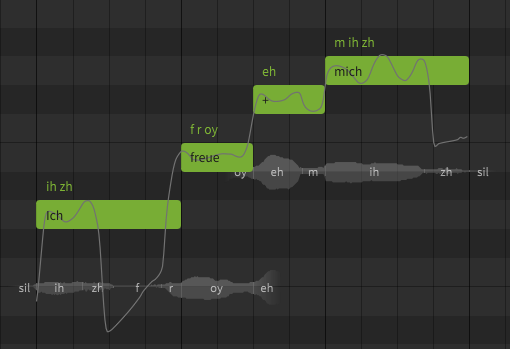
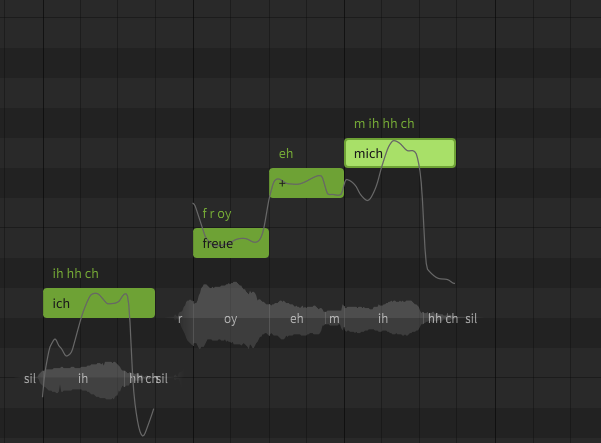
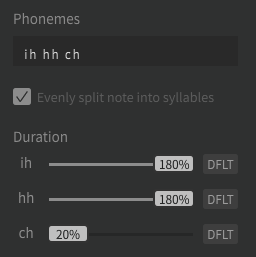
You can get closer to the German pronunciation with the following phonemes, although of course you can still hear a clear English accent
I randomly chose the example with Solaria, but with another VoiceDB it could be completely different.
In this respect, it would be difficult for a non-native speaker to immediately find suitable phonemes for a German text.
An update that improves German pronunciation would be worth a lot to me!
For example, I use Synth V pro to create demo versions for a choir. Many pieces from the repertoire are in German.
The German dictionary provided by Eclipsed Sounds is automatically generated. That is to say, they likely cross-referenced a list of German words and their respective IPA pronunciations with the English phonemes in SynthV Studio on a “closest similar sound” basis. This is why the dictionary is so large, but makes somewhat naive assumptions about German pronunciation.
For a new language to be supported, there’s a significant amount of R&D work that needs to be done, as shown by the time and effort that has gone into the introduction of Cantonese by Dreamtonics and Spanish by Eclipsed Sounds.
I expect we’ll slowly see more languages added, but it’s probably a rather unique challenge to find partners with the necessary expertise to make it a reality and accelerate the process, and as more languages are added there’s the added challenge that the next language may not be spoken by any of the existing staff, requiring additional consultation or partnerships.
AI may also speed up the process here. Thanks to the stem separation software available on the market, a large number of solo singing pieces can now be made available that should be suitable for training the new language. In any case, I’m excited to see what happens in this area in the near future.
Not for this use case though. Commercial vocal synths only use recordings they have the rights to in the dataset, and the added noise or artifacts in the source material would make for a poor quality product (cleaning the samples is already a big part of the work that goes into making a voice database, and that’s with studio recordings).
Using isolated vocals from songs they don’t have the rights to could very easily end up with Dreamtonics in legal trouble. Image generators get away with it because independent artists largely don’t have the means to defend their copyright; the same cannot be said for music labels.
How did text-to-speech programs achieve their incredible authenticity? Certainly not with a speaker who has read out every conceivable combination of words, but by evaluating a huge number of spoken audio recordings.
This is how I (in my simplicity) wanted to imagine Synth V: an AI model is trained with a large number of anonymized vocal recordings and the pronunciation is then “imprinted” on a specific voice. But it doesn’t seem to be that simple…
Be patient, my friends. I just finished the German Schlager Hit “Wahnsinn” by Wolfgang Petry and used Kevin as singer. Needs a little bit of tweaking but then I will upload it on Youtube and see what happens.
Unless a native German singer is used to build the voice library, you will never capture the German accent no matter which phonemes you use.
Same with French.
Unless Dreamtonics believe it is commercially viable to produce a German voice library you’ll only ever get an English or Chinese pronunciation of German words (or whatever the native language of the original singer)
I would love to have a UK English voice but I doubt it will happen.
You can tame the American accent to a degree but ‘r’ for example, will always sound American despite being English.
His voice isn’t low, but rough, comparable to Ozzy.
As discussed in another forum, I would like a Rock voice in the style of Chris Robertson of Black Stone Cherry … rough and a bit lower. Ninezero’s voice is pretty high for a Rock voice … as I said very similar to Ozzy.
Fact is, I don’t like all other male voices being available, except Saros, which is the most versatile IMO. Asterian is something for Black Music and the others sound like a boygroup … LOL.